一些基础知识
学习堆排序,总要了解堆的数据结构吧,了解堆又需要了解二叉树的基本知识,了解二叉树要先知道树是个什么东西吧…… 呃,还是太年轻。这里简单谈谈吧。
呃,还是太年轻。这里简单谈谈吧。
二叉树
- 提一下树——树是一对多的数据结构,从一个根结点开始,生长出它的子结点,而每一个子结点又生长出各自的子结点,成为子树。如果某个结点不再生长出子结点了,它就成为叶子。
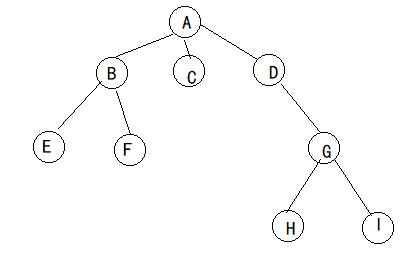
二叉树是每个节点最多有两个子树()的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree),且次序不能颠倒。
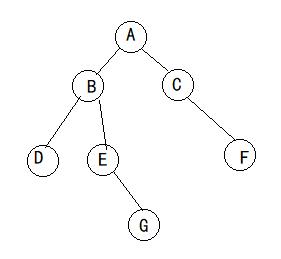
完全二叉树除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点。
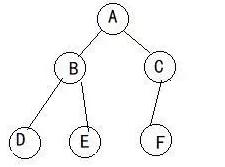
满二叉树的所有分支结点都既有左子树又有右子树,并且所有叶子都在同一层。每一层上的节点数都是最大节点数 。
堆排序
数组与堆结构 (如何用数组实现):
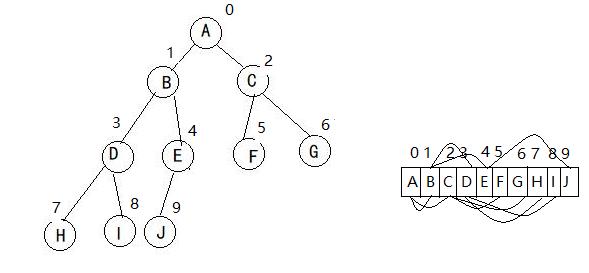
- 子节点:左孩子是2*i+1,右孩子是2*i+2
- 父节点:(i - 1) / 2
生成大根堆:
堆可以分为大根堆和小根堆。在大根堆中,所有子树中子节点的值都小于等于父节点;而小根堆的组织方式恰好相反:所有子树中子节点的值都大于等于父节点。在堆排序中,使用的是大根堆;而小根堆常被用作构建优先队列。
调整大根堆的过程,遍历数组元素,将当前节点与其父节点进行比较:
- 若当前节点小于等于父节点,则比较下一位置。
- 若当前节点大于父节点,则将当前节点与父节点交换,然后比较交换后的父节点(交换前的“当前”节点)与其父节点进行比较(交换)过程。这个过程很明显可以是个递归过程。
下面是该过程的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
private void heapInsert(T[] arr, int index, Comparator<T> comparable) {
int parent = (index - 1) / 2;
if (comparable.compare(arr[index], arr[parent]) <= 0) {
return;
}
swap(arr, index, parent);
heapInsert(arr, parent, comparable);
}
private void heapInsertByLoop(T[] arr, int index, Comparator<T> comparable) {
int parent = (index - 1) / 2;
while (comparable.compare(arr[index], arr[parent]) > 0) {
swap(arr, index, parent);
index = parent;
}
}
|
容易想到的是,调整完毕后的树仍然是无序的。但是可以理解的是根节点一定是整个树(数组)的最大值,那么我们完全可以利用上述过程查找最大值,然后将与树的最后一个节点交换。再对除最后一个节点的前n-1个树节点(将树的规模缩小1,size–)进行大根堆调整,再交换。循环执行此过程,即可使得元素升序排列。
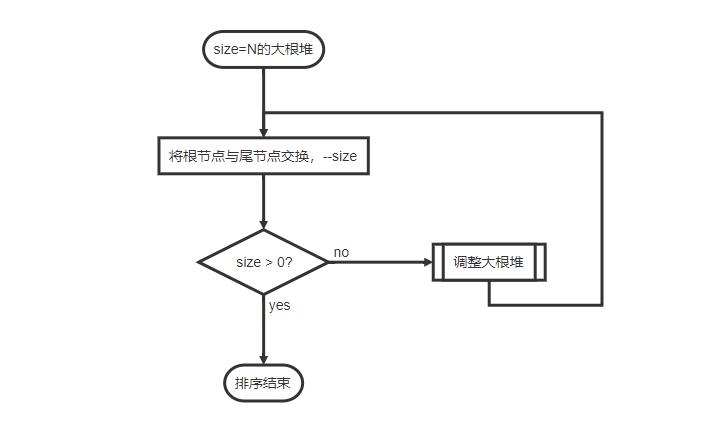
值得注意的是,大根堆生成过程中的调整策略,是将当前元素与父节点比较(由底向上),利用该策略同样可以完成上述排序过程,流程如下:(构建大根堆 -> 交换)
1
2
3
4
5
6
7
8
| st=>start: size=N的大根堆
op=>operation: 将根节点与尾节点交换,--size
cond=>condition: size > 0?
e=>end: 排序结束
sub=>subroutine: 调整大根堆
st->op->cond
cond(yes)->e
cond(no)->sub->op
|
<!–> <–>
<–>
具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Override
public void sort(T[] array, MangoComparable<T> comparable) {
if (array == null || array.length < 2) {
return;
}
for (int i = 0; i < array.length; i++) {
heapInsert(array, i, comparable);
}
int heapSize = array.length;
swap(array, 0, --heapSize);
while (heapSize > 0) {
for (int i = 0; i < heapSize; i++) {
heapInsert(array, i, comparable);
}
swap(array, 0, --heapSize);
}
}
|
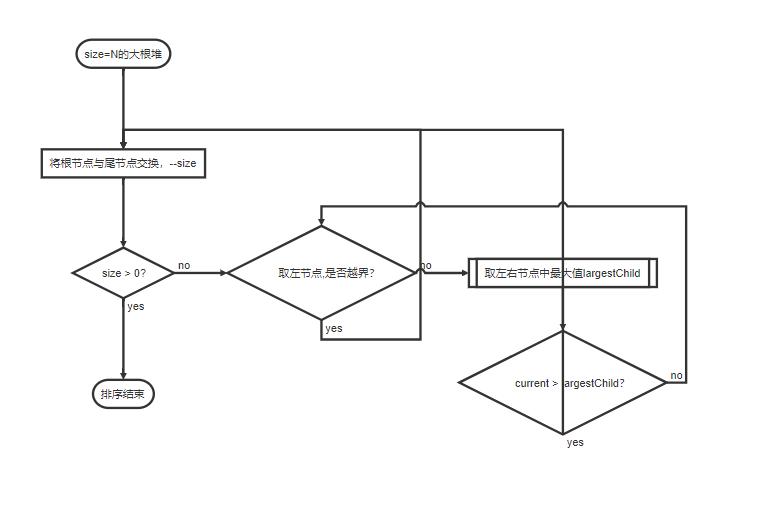
而在排序过程中,我们当然也可以便利地比较左右子树与父节点即,当前节点(由顶向下,毕竟此时我们已经生成了堆结构了)。找到当前节点的左右节点中较大的子节点,与当前节点比较:
- 若当前节点大于等于较大的子节点,则判断下一个节点。
- 若当前节点小于较大的子节点,则将当前节点与较大的节点交换(我们的目标是让最大值向上浮)。然后比较交换后的所产生的父节点(交换前的较大的子节点)与其子节点进行比较(交换)。
具体流程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| st=>start: size=N的大根堆
op=>operation: 将根节点与尾节点交换,--size
cond=>condition: size > 0?
e=>end: 排序结束
subcond1=>condition: 取左节点,是否越界?
sub2=>subroutine: 取左右节点中最大值largestChild
subcond2=>condition: current > largestChild?
st->op->cond
cond(yes)->e
cond(no)->subcond1
subcond1(yes)->op
subcond1(no)->sub2
sub2->subcond2
subcond2(yes)->op
subcond2(no)->subcond1
|
<!–> <–>
<–>
具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| @Override
public void sort(T[] array, MangoComparable<T> comparable) {
while (heapSize > 0) {
heapify(array, 0, heapSize, comparable);
}
}
private void heapify(T[] arr, int index, int size, MangoComparable<T> comparable) {
int left = 2*index + 1;
if (left < size) {
int largestChild = left + 1 < size
&& comparable.compare(arr[left+1], arr[left]) > 0 ? left+1 : left;
if (comparable.compare(arr[largestChild], arr[index]) < 0) {
return;
}
swap(arr, largestChild, index);
heapify(arr, largestChild, size, comparable);
}
}
private void heapifyByLoop(T[] arr, int index, int size, MangoComparable<T> comparable) {
int left = 2*index + 1;
while (left < size) {
int largestChild = left + 1 < size
&& comparable.compare(arr[left+1], arr[left]) > 0 ? left+1 : left;
if (comparable.compare(arr[largestChild], arr[index]) < 0) {
return;
}
swap(arr, largestChild, index);
index = largestChild;
left = 2*index + 1;
}
}
|
时间复杂度分析
我们知道二叉树结构的基础操作时间复杂度为O(logN),其中N是树的节点数。大根堆的生成过程相当于不断向树中增加节点的过程,即
1
2
3
4
5
| 数组中下标为0的元素,插入高度为0的二叉树;
数组中下标为1的元素,插入高度为1的二叉树;
数组中下标为2的元素,插入高度为2的二叉树;
……
数组中下标为n-1的元素,插入高度为n-1的二叉树;
|
所以,该操作时间复杂度为O(log1 + log2 + ... + logi + ... + logn) = O(logn!),经数学证明(logn!和nlogn “同阶函数”),因此生成大根堆的时间复杂度是O(nlogn)。